
Dry-struct use cases

Excursus
A few days ago I meet a friend of mine. He has several questions for me and my experience. Almost all of them relate to the job I’ve done recently. Despite the fact the questions are from various topics, I catch myself giving almost the same answer to all of them. It sounds like, “Use dry-struct”. After that, I remember I’ve told similar stories to other people before. That makes me very surprised and anxious, because I realize how important and useful this tool is. Unfortunately, some of my friends even don’t understand why this tool exists at all.
In this post, I’m trying to reveal these questions and answers for people already seeking the same information as my friend did. I also set a goal to show what problems dry-struct actually solves to people not understanding its motivation. I want to show why this tool is very important and why it’s a step forward to a much more comfortable development process in Ruby world.
Questions and answers
1. Andrei, I’ve heard you have experience with GraphQL. But what is your attitude to it? I prefer JSON API and don’t see GraphQL benefits.
Well, first of all before comparing them one should understand that JSON is just a format that specifies data. And usually this data is supposed to go from one “program/service/server/process/whatever” to another “program/service/server/process/whatever”. Let’s agree on “program/service/server/process/whatever” is a black-boxed service that can be either back-end or front-end process and from now on we call it just process.
Note, processes can be written in different programming languages as JSON is language-agnostic. Basically, this is just a set of rules that specify data going from Process A to Process B (more about JSON is in rfc7159):

The red pipe in the picture above is a transport protocol responsible for data delivery. And inside this pipe some data interchanges in JSON format. That’s it, JSON is only just a properly formatted string, nothing more. Note, the protocol can be HTTP, RPC, AMQP, etc., and even just a method call inside the same process!
But before sending this string a process needs to build it from objects residing in its memory. That action is called serialization. Moreover, a process that receives the data needs to build corresponding objects inside its memory back. That action is called deserialization. Fortunately, for these actions, there are ready tools for almost all programming languages. Ruby and JavaScript are not exceptions here.
Unfortunately, a properly serialized JSON doesn’t guarantee correct functioning of the process deserializes it. Consider the following scenario. There is defined JSON data {title: "A post", body: "Some text"}. It’s good now for both processes: a process-sender freely serializes it and a process-receiver freely deserializes it. The processes themselves are working properly in integration, i.e. they are speaking the same language. Now, something changes on the sender side and the “title” field gets renamed to “name” spontaneously. With dynamic programming languages, a spontaneous change like that happens often, especially when the data is generated by some “magic” (hello, Ruby!). So the data structure implicitly changes to {name: "A post", body: "Some text"}. Now, what does happen with the receiving side, if these changes are not aligned? Of course, it fails. In the case of JavaScript, it processes the data improperly showing an empty title instead of expected “A post” on UI. In any case, an innocent change introduces a bug.
How to prevent this issue? Manual testing? For sure, it’s possible to test everything manually. Whenever something changes, someone needs to run the corresponding processes and see if they work in integration. It’s maybe ok if there are only two processes like for a Web application - back-end is on Ruby and front-end is on JavaScript. It’s not a problem to open a browser and click around. But even that doesn’t guarantee there is no regression. Usually, there are some tricky scenarios or not popular places easy to forget, especially when there are missing testing scenarios. It’s easy not to spot a tiny thing on UI that at first glance looks correct, but in fact, it’s wrong. Therefore, someone needs to read the code of the receiving processes and exclude usage of the old name in all places.
If it’s not much code and there are no many processes, this may be acceptable. But if there are many processes? For example, additionally to our Web UI there are iOS, Android, with hundreds of versions, etc. And for each process, there is a separate responsible person/team. Then this an easy task to check for regression turns into a painless and long activity. It leads to unnecessary communication and monkey business in the flesh of manual testing.
Eventually, manual testing doesn’t guarantee anything, because there is always a chance to miss something. Remember, the change in the example above happened spontaneously. Nobody knows about this change in the data at all! It’s easy to miss the bug and deploy on production without manual testing.
This is a typical case in Rails world: a field gets renamed on a table, the unit tests are run and green, the code is read on the back-end side, and it’s guaranteed that nothing uses the old field on the back-end side. Deploy to production, open a browser, and oops :(
Integration tests would solve this issue if they had covered related code to the change. This is a much more powerful approach and carefully written scenarios may solve the issue entirely. There are downsides of integration tests, though. First, they run too slow. That’s why they may impact the development cycle. Second, the high cost that consists of maintenance, CI time, and implementation. Despite these obstacles, this is a very important part of an application with production deployment. It helps to make code changes confidently not giving harm to the business.
But it’s possible to reduce the cost. If the processes talked between each other by some contract, its violation would mean that integration is broken immediately:
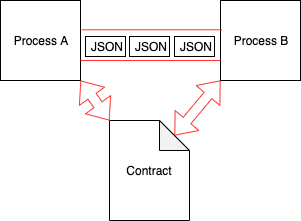
A contract here is some specification that’s understandable for both processes. It supposes to fail instantly if the data doesn’t correspond to the contract during serialization or deserialization.
And here GraphQL comes into play. The point is that it has an implementation of a contract like that out of the box. It’s called “schema” there. It’s not possible to generate or receive data that doesn’t correspond to the schema. If the schema takes part in the unit tests, smoke testing is enough to make sure the integration works. And these tests are much cheaper.
This is not the only thing GraphQL solves out of the box. The schema is actually a set of all possible fields connected with each other. All the charm of GraphQL is that a receiving process can specify only those data it needs, no less no more. And for all of that, there is only one endpoint instead of a forest REST endpoints with weird names.
In my opinion, the winner is GraphQL here. It’s highly recommended for a sustainable relatively big application. But for MVP or PoC it may be redundant.
One might argue there are other commonly accepted ways to build a contract like that: Pact, JSON-schema, Swagger, and others. But they are subtly different from GraphQL. They are fixing the problem with JSON by adding one more complex technology to an already complicated stack. With GraphQL we have just one technology (not an easy one, though) that has everything necessary built-in.
For those who are convinced this a technology worth to look at, there is an official place to start with.
Ok, but how all of that relates to dry-struct? It turns out, a structure defined with dry-struct is a schema as well. It has fields with known types and connections between them, similar to GraphQL. It’s easy to serialize data into and deserialize from JSON.
What eventually means, dry-struct can be used with the same respect as GraphQL for communication between processes. But with one caveat. The both ends should be written in Ruby. This way it would be possible to share dry-struct between sending/receiving processes, so that the transmitted data can be easily validated against the schema. Otherwise, we would need to synchronize a dry-struct schema between a place it’s defined (in Ruby, of course) and a place cannot reuse Ruby definitions. To implement this kind of synchronization, there should be made some tool transforms the dry-struct schema to a commonly used format this other language supports.
Briefly speaking, GraphQL and dry-struct are tools allow to define a strict API between processes. With a strict API it’s easier to maintain the code, and add new functionality. By strict I mean instant feedback about possibility or impossibility for a change in the code.
Now, consider there is only one Ruby process and internal method calls are used for data interchange. This situation is possible when a monolithic application is split into isolated modules communicate via some “remote” protocol. In this case, a structure specified by dry-struct can be used as an API schema and a contract, JSON can be used as a data transport format.
This is how it was implemented on a project from my experience:
- the dry structs are defined in a “repository1”
- “repository2” and “repository3” are just Ruby applications having “repository1” as a dependency, so that any change in the “schema” should be aligned in these repositories
- for convenience, all the “repositories” are kept in one git repository, so that:
- it’s easy to grep all the code at once and spot the places require changes after a schema change
- no need in manual update dependencies on “repository2” and “repository3”.
But this is not all. If picture just one Ruby process that calls only internal methods, dry-struct can be used as a value object. And again, as the structs are strict, we can talk about a reliable internal API. With almost the same respect as typed languages have.
2. What’s your preference for validating, preparing, and processing parameters coming from another process?
dry-schema is my leading preference here. It’s like dry-struct, has the same base that’s dry-types, has the same philosophy, but has a bit prettier DSL and API for validating params. Also, it’s easier for beginners.
I’m not a fan keeping validations and callbacks on the model layer. Models can be used in different contexts that don’t need some of the callbacks or validations. So, it’s reasonable to define callbacks and validations inside these contexts instead of having spaghetti in one place. Although, it’s reasonable to leave some validations on the model layer if they are true in all contexts. If follow this rule, the code becomes easier to maintain and extend.
Check out this snippet to feel the idea:
PostSchema = Dry::Schema.Params do
required(:title).filled(:string)
optional(:body).filled(:string)
end
class CreatePostOperation
def initialize(params)
@params = PostSchema.call(params)
end
def peform
raise ParamsError.new(params.errors.to_h) unless params.success?
Post.create(params.to_h)
end
end
The PostSchema is a contract between the receiving process and another process sends the params. This contract specifies a set of rules such as:
- required and optional fields
- types of these fields
- automatic coercing of the given parameters according to the specified types
- if a parameter has a wrong type, or a value that’s impossible to typecast to the specified type, it’s considered as a validation error.
Note, besides the params validation we get also manageable typecasting for free. By manageable here I mean an official possibility to add custom coercing rules or types without monkey patches. Keep in mind, Rails doesn’t have this possibility.
The CreatePostOperation is supposed to be used in a controller responsible for handling requests from other processes. Its implementation is simplified a lot here just for the sake of providing the idea. In reality, an operation like that has more things to take care such as:
- open DB transaction or not in
#perform - exit softly without exceptions providing an interface to fetch the errors
- bypass errors from the model layer. Remember, the
Postmodel above can still have validations or there are may be constraints on DB level. - catch particular exceptions and extract errors from there to expose them through the interface similar to model validations
- other.
3. I’m familiar with dry-struct but it cannot serialize data from my objects. How do you serialize into dry-struct?
That’s true. dry-struct doesn’t have this functionality out of the box. But this is not a big deal as it’s easy to implement:
class BaseStruct < Dry::Struct
def self.to_hash(object, type = self)
type.schema.each_with_object({}) do |key, res|
name = key.name
attr = key.type
if array?(attr)
values = ::Array.wrap(object.public_send(name))
res[name] = values.map { |value_item| serialize(value_item, attr.member) }
elsif bool?(attr)
value = object.public_send("#{name}?")
res[name] = value
else
value = object.public_send(name)
res[name] = serialize(value, attr)
end
end
end
private
def serialize(object, type)
complex?(type) ? to_hash(object, type) : object
end
def complex?(attribute)
attribute.respond_to?(:<) && attribute < BaseStruct
end
def bool?(attribute)
attribute.primitive?(true)
end
def array?(attribute)
attribute.primitive?([])
end
end
class Types
include Dry.Types()
end
class PostStruct < BaseStruct
attribute :title, Types::String
attribute :body, Types::String.optional
end
The main function here is BaseStruct.to_hash as you’ve probably guessed. It’s just a recursive function traverses all the defined attributes. Just start using it: PostStruct.to_hash(Post.last).to_json. Pay attention, the serializing object should have defined all methods that are specified on the struct. In this example, there are title and body attributes defined on the struct, so that the Post instance should respond to these both methods and return values with the specified types.
Note, a complex attribute should inherit from BaseStruct like that:
attribute :metadata, BaseStruct do
attribute :writer_id, Types::Integer
attribute :created_at, Types::Time
end
To get the whole picture check out the example how to deserialize:
PostStruct.new(JSON.parse(params))
Also, one more advice for people already tried dry-schema or dry-struct. At first glance, they may look scary because of types diversity. All types there don’t exist in global scope as in Ruby. For example, in Ruby there is String and that’s it, it’s String everywhere. In dry-struct/dry-schema types relate to groups: nominal, strict, coercible, params, json, maybe. More about this is here. The difference between them is how much they are strict and if automatic typecast is possible.
For JSON serialization and deserialization we need strict and coercible types. But not all default dry-struct types satisfy these requirements. For instance, there is no strict and coercible Date out of the box. Fortunately, we can combine them: Date = Strict::Date | JSON::Date. And if put this code under the Types class above we can come up with the following elegant code:
class Types
include Dry.Types()
Date = Strict::Date | JSON::Date
Symbol = Strict::Symbol | JSON::Symbol
Time = Strict::Time | JSON::Time
Decimal = Coercible::Decimal
end
And now all types under the Types:: space are strict and coercible. We shouldn’t worry about from which group to take a type while specifying attribute.
4. Ruby debugging is a pain. Can you recommend something to reduce the time spending on that?
Of course, I can. Use dry-struct! Seriously, strictly defined structures in the code make it much more readable that reduces debugging time drastically. Which type is used and where becomes clear almost immediately after the first look at the code. If the signature of the methods receiving these structures is documented, we get almost statically typed language out of the box. So we benefit from both worlds: dynamic and static.
Example of methods signature documentation in YARD format:
# @param post_params [PostStruct]
def publish(post_params)
By the way, documenting just methods signatures is good. But documenting methods themselves from a business point of view also brings a lot of benefits. If you still don’t document your code, I invite to start doing that. You will see how you are becoming a better developer.
Conclusion
Dry-rb ecosystem is huge. In this post, we’ve touched only parts of it: dry-struct, dry-schema, and implicitly dry-types. I hope you’ve seen benefits these tools bring to Ruby world. In short, they borrow a missing part from static programming languages - types. That makes programming in Ruby much more comfortable and confident. As a result, it reduces pain in terms of bugs and debugging time.