
How we reconciled app users with Stripe and prevented financial losses

- Possible discrepancies in Stripe integrations
- Stripe integration state of our application
- The plan to reconcile data with Stripe
- Stripe data store preparation
- The Stripe data scrapper
- Run the script automatically
- Analyze Stripe data discrepancies with SQL
- Fixing the data deviations between the app and Stripe
- Preventing future discrepancies
- Conclusion
Possible discrepancies in Stripe integrations
Stripe integrations often experience data consistency issues, such as users being on different subscription plans in the app compared to Stripe. This misalignment can lead to lost revenue or jeopardize customer success stories.
For example, a customer may have a premium status within the app, while Stripe shows no active subscription. This type of discrepancy can lead to lost revenue for the business. Another potential issue occurs when a customer overpays. In this case, the customer is on the free plan within the app but has an active subscription to the premium plan in Stripe, jeopardizing the customer success story.
Stripe integration state of our application
This blog post outlines the approach we took to resolve such issues in our app, which had around 80k users, with 10% on the premium plan. We identified instances of both overpayment and underpayment, which could be attributed to manual data manipulation in Stripe, missing webhooks, or bugs in our system.
The plan to reconcile data with Stripe
While we used Ruby for scripting, this solution is universal and can be applied to applications written in other languages like Python, Node.js, Java, Rust, and Go.
Our plan is the following:
- Fetch all relevant data from Stripe via Stripe REST API. In our case that included all customer entities and their subscriptions.
- Put the fetched data into our database. To avoid polluting the main database schema, use a separate namespace for these tables. In fact, PostgreSQL refers to this namespace concept as
schema. The default schema ispublic. We create thestripeschema and necessary tables inside it. - Analyze the discrepancies using SQL queries. SQL is not only faster and less prone to bugs for this kind of task in terms of data processing but also in development. This means we will obtain results faster with fewer expenses for the business.
- Configure Metabase for these reports. Metabase is the system we use to write SQL and build reports. Set up notifications for data discrepancies so that we receive alerts about new cases and can react to them as soon as possible. Luckily, it was already set up for this project. The good news is that its setup takes very little time.
- Schedule the data scraper from Step 1 to run automatically every week.

Stripe data store preparation
First, we need to create the DB schema along with the Stripe tables. This is the SQL script we used for that:
create schema stripe;
create table stripe.customers (
id serial not null,
stripe_id varchar(250),
email varchar(250) not null,
created_in_stripe timestamp,
description varchar(250),
metadata jsonb,
deleted boolean,
created_at timestamp default current_timestamp,
updated_at timestamp default current_timestamp
);
create table stripe.subscriptions (
id serial not null,
stripe_id varchar(250),
stripe_customer_id varchar(250),
plan_id varchar(250),
status varchar(250),
created_at timestamp default current_timestamp,
updated_at timestamp default current_timestamp
);
Inside the Rails app, data migrations could be created for this purpose. However, as we are unsure whether these tables are permanent at the moment, we use SQL and execute it manually on the server.
Our app uses Rails, so it has ActiveRecord, and we can point our models to these tables. These are the ActiveRecord models we created for our convenience while working with these tables in the Ruby script:
class StripeSchema < ActiveRecord::Base
self.abstract_class = true
establish_connection :stripe
end
class StripeCustomer < StripeSchema
self.table_name = :customers
self.primary_key = :id
end
class StripeSubscription < StripeSchema
self.table_name = :subscriptions
self.primary_key = :id
belongs_to :stripe_customer, foreign_key: :stripe_id
end
We have a special folder in the app, app/scripts, where we put this kind of ad-hoc code. Later, we use Rails runner to execute them on the production server against the real data. They can also be run locally for testing purposes during script development. This script code was put into app/scripts/stripe_classes.rb file.
The Stripe data scrapper
And this is the script we’ve come up with:
starting_after = nil
loop do
params = {expand: ['data.subscriptions'], limit: 100}
params[:starting_after] = starting_after if starting_after
customers = Stripe::Customer.list(params)
customers.each do |cus|
ApplicationRecord.transaction do
StripeCustomer.create(
email: cus["email"],
stripe_id: cus["id"],
description: cus["description"],
created_in_stripe: cus["created"] ? Time.zone.at(cus["created"]) : nil,
metadata: cus["metadata"],
subscriptions: customer_subscriptions,
deleted: cus["deleted"]
)
cus.subscriptions.each do |sub|
StripeSubscription.create(
stripe_customer_id: cus["id"],
stripe_id: sub["id"],
plan_id: sub["plan"]["id"],
status: sub["status"]
)
end
end
starting_after = cus["id"]
end
break if customers.count < 100
end
This script fetches all Stripe customers along with their subscriptions. Later, using this data, we can compare it against our app’s database and identify any deviations.
We run this script on the server with the rails runner. Its run can take a while. Not to get the process killed with a closed SSH connection to the server, we use screen utility. At least for the first time, we have to run it manually and monitor for any failures. If there are any issues, we fix them. This way, we verify that the script is valid and reliable. Later, we can automate it to run on a schedule. We’ve collected data on 85k customers and 8.5k subscriptions, and it took around 1 hour. Not bad for this amount of data.

Run the script automatically
After some preliminary data analysis and verification of its correctness, we can set up this script to run automatically on the server. We use sidekiq and its extension sidekiq-scheduler for this, as it’s already in place. The app also has Rollbar configured to monitor exceptions and errors, so if something goes wrong, we can be notified.
This is the job:
class UpdateStripeData
include Sidekiq::Worker
require_relative '../../scripts/stripe_classes'
def perform
drop_old_data
record_stripe_data
end
private
def record_stripe_data
starting_after = nil
loop do
params = {expand: ['data.subscriptions'], limit: 100}
params[:starting_after] = starting_after if starting_after
customers = Stripe::Customer.list(params)
customers.each do |cus|
ApplicationRecord.transaction do
StripeCustomer.create(
email: cus["email"],
stripe_id: cus["id"],
description: cus["description"],
created_in_stripe: cus["created"] ? Time.zone.at(cus["created"]) : nil,
metadata: cus["metadata"],
subscriptions: customer_subscriptions,
deleted: cus["deleted"]
)
cus.subscriptions.each do |sub|
StripeSubscription.create(
stripe_customer_id: cus["id"],
stripe_id: sub["id"],
plan_id: sub["plan"]["id"],
status: sub["status"]
)
end
end
starting_after = cus["id"]
end
break if customers.count < 100
end
end
def drop_old_data
ActiveRecord::Base.connection.execute(<<~SQL)
delete from stripe.customers;
delete from stripe.subscriptions;
SQL
end
end
And this is the configuration defined in config/sidekiq_scheduler.yml to run it every Saturday at 12:00PM in UTC time zone:
production:
update_stripe_data:
class: UpdateStripeData
cron: '0 12 * * 6'
We chose that time as the servers are less loaded during those hours.
Analyze Stripe data discrepancies with SQL
We are all set. With the data in place, we can use SQL to identify all deviations. This will involve using common table expression (CTE), views, joins, filters, and aggregation functions.
Note that the script fetches the Stripe data once a week, and it takes around 1 hour to run. Consequently, the app data will always be ahead of the Stripe data. This is crucial to understand because we cannot join the current app data against the cached Stripe data due to this time lag. Therefore, we need the app data snapshot at the moment the script was run.
Creating a real data snapshot is an option, but it would significantly complicate our architectural story. Fortunately, we have Papertrail configured in the app, a gem that stores all changes to users. This means we can reinstall actual data at the moment the script fetched Stripe data was run. The only field of interest for us is plan_id. Therefore, we reinstall only this field. To reuse the reinstalled data, we utilize views. These are kind of virtual tables inside SQL but don’t store the collected data:
create view stripe.users_with_actual_plan as (
with stripe_update as (
select created_at as ts from stripe.subscriptions limit 1
),
recent_versions as (
select * from versions where created_at >= (select ts - interval '1 day' from stripe_update)
),
data as (
select
u.*,
coalesce (
coalesce(
coalesce(
(substring((vp.object_changes->>'plan_id') from ', (\d+)'))::int,
(substring(vp.object from '\nplan_id: (\d+)'))::int
),
coalesce(
(substring((vf.object_changes->>'plan_id') from '(\d+),'))::int,
(substring(vf.object from '\nplan_id: (\d+)'))::int
)
),
u.plan_id
) as actual_plan_id,
rank() over (partition by u.id order by vp.created_at desc nulls last, vf.created_at asc) as version_rank
from users u
left join stripe.customers c on c.stripe_id = u.stripe_customer_id
left join recent_versions vp on vp.item_id = u.id and vp.created_at < coalesce(c.created_at, (select ts from stripe_update))
left join recent_versions vf on vf.item_id = u.id and vf.created_at >= coalesce(c.created_at, (select ts from stripe_update))
) select * from data where version_rank = 1
);
This SQL query might look intimidating, and that’s okay. It’s not essential for understanding everything here. All you need to know is what it does, and you already have that knowledge. It creates a virtual table of users with the actual plan_id that was set just before the script fetched Stripe data.
One might ask, “How do we end up creating SQL queries that appear so complicated and intimidating?” The answer is simple: through small steps, selecting one field at a time, joining step by step, and eventually combining them into a single query using the CTE construction.
And now, we are ready to join these users with the actual plan data from Stripe.
This time, the SQL looks much easier:
with stripe_update as (
select created_at ts from stripe.subscriptions limit 1
)
select u.* from
stripe.users_with_actual_plan u
left join stripe.subscriptions s on s.stripe_customer_id = u.stripe_customer_id
where u.actual_plan_id is not null and u.actual_plan_id not in (6, 121)
and u.created_at < (select ts from stripe_update)
and s.id is null
;
The plan with ID = 6 is the free plan, and 121 is a technical one used only for internal purposes. Therefore, the entire expression u.actual_plan_id is not null and u.actual_plan_id not in (6, 121) indicates that the user is on a paid plan.
We inputted this SQL into Metabase, and this is what it looks like:
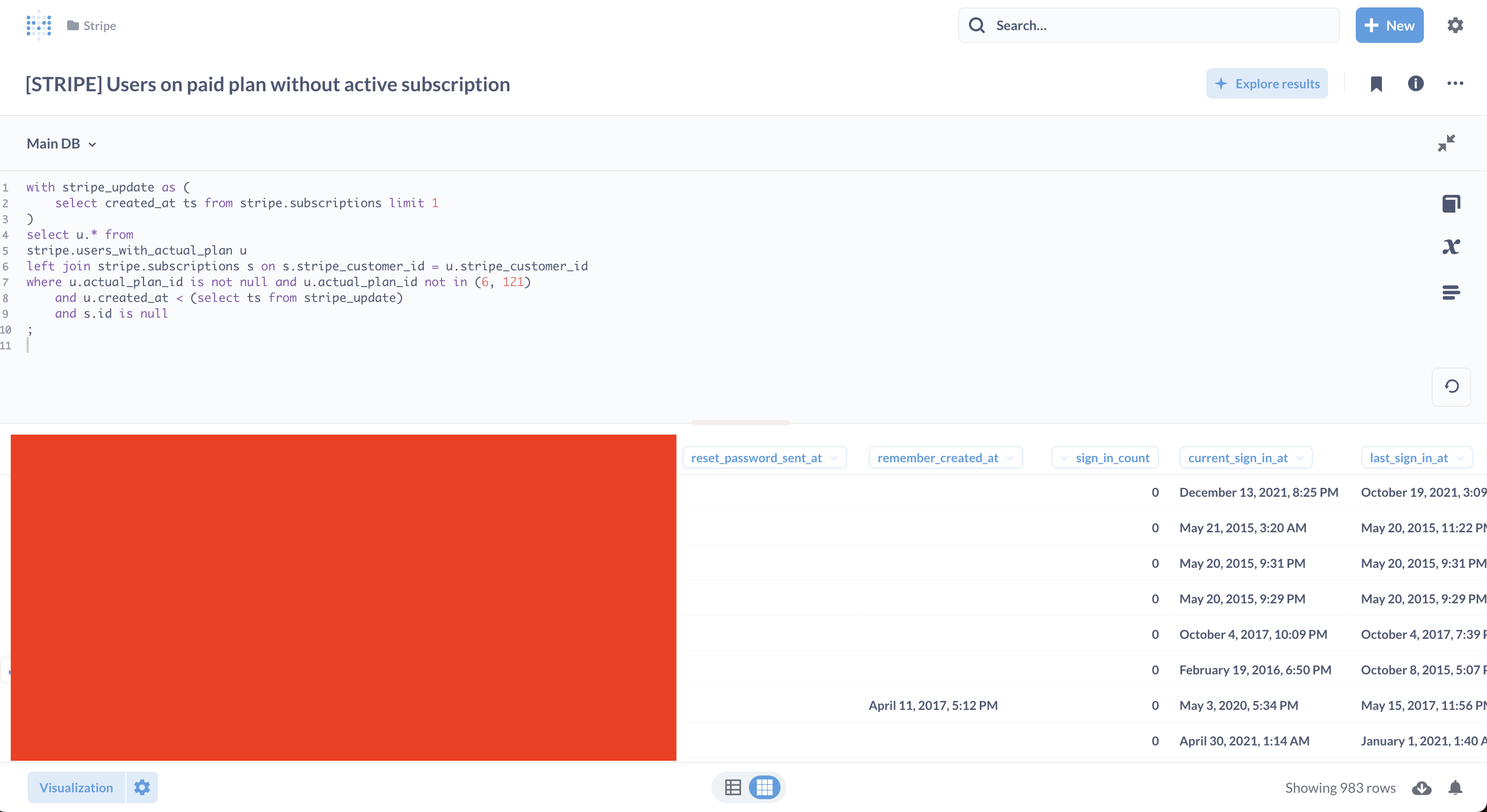
Optionally, we can configure notifications to be sent even when a new record is added to these results. See the bell icon at the bottom right; it’s intended for this purpose.
Metabase comes in handy for exporting data into CSV and Excel with just one click. We do that often. That simplifies communication with the business a lot. It’s also possible to share the reports right away with the team via a direct link.
As we can see, there were 983 instances of user data discrepancies found. It’s a significant amount of data among all active subscriptions that match the app user data, which is 8,488. That represents roughly a 10% margin of error! Too much!
We found the number of subscriptions that match user data using this SQL:
with stripe_update as (
select created_at ts from stripe.subscriptions limit 1
)
select count(u.*) from stripe.users_with_actual_plan u
join stripe.subscriptions s on s.stripe_customer_id = u.stripe_customer_id
join plans p on p.stripe_price_id = s.plan_id
where u.created_at < (select ts from stripe_update)
;
See how the created view “users_with_actual_plan” becomes handy here as well. It’s a very powerful tool that can save a ton of code and coding time!
Further data analysis shows that 514 of these 983 discrepancies are related to deleted users. It turns out our app employs a so-called soft delete feature, meaning they are not actually deleted but marked as such, preventing them from using the app anymore. Well, now the situation looks much better. It’s just a 5% margin of error, not the 10% we initially thought. It’s almost within 3% of the standard deviation. Not so bad.
Fixing the data deviations between the app and Stripe
All actions related to fixing data require a thorough understanding of the app at a good level. We can either examine the instances of discrepancies one by one, allowing us to understand what happened to each of them. When we analyze each instance of discrepancy, we check the app database, logs, Papertrail records, Stripe logs, Rollbar, and any other data sources that could help us determine what happened to a certain user.
By simply looking into the app database, we noticed those 514 softly deleted users. This can be easily done by examining the deleted_at column in the report. Any Excel-like tool can allow us to filter this information, or we can accomplish this in Metabase.
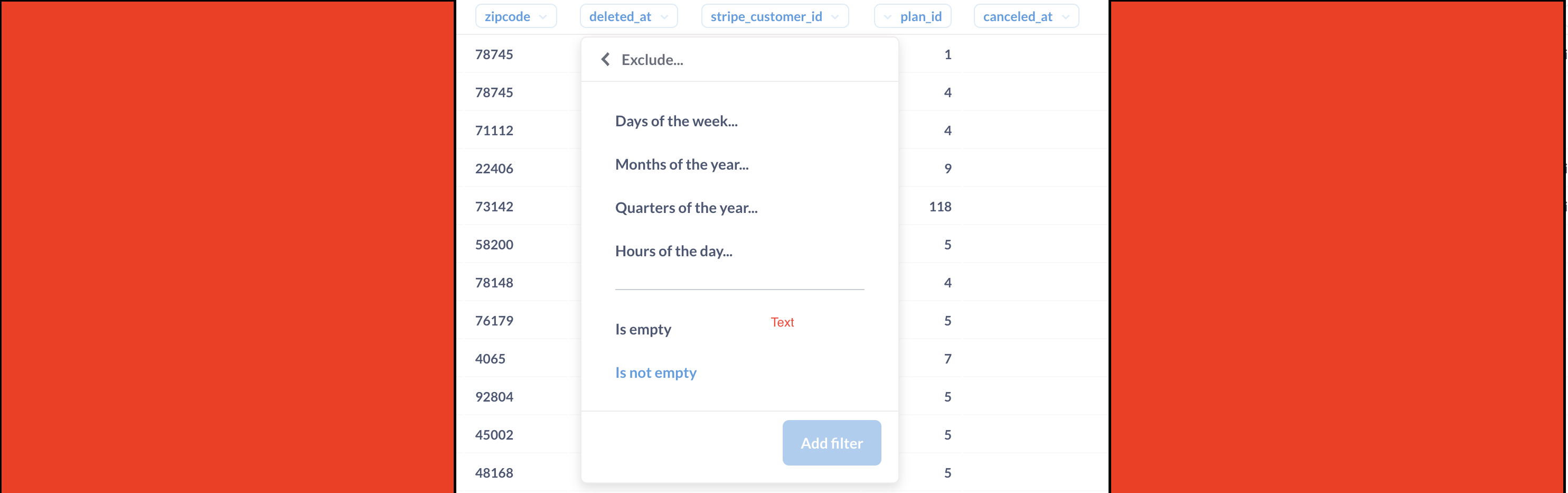
We can move these users to free plan right away by writing a Ruby script that was successfully done.
Now, there are only 469 records with data discrepancies remaining. We go through some of them. That shows that all of them indeed had data discrepancies. Delving into the codebase with some hypotheses about what happened, we spot a serious breach inside the app. Each Stripe webhook has its own handler with specific code manipulating the user subscription data. All processed by Sidekiq. But Sidekiq doesn’t guarantee the order of incoming webhook processing.
At this point, we decide to address this issue by making slight adjustments to the architecture. From now on, all webhooks will be processed by one handler that consistently checks the actual Stripe subscription state before changing the user’s plan within the app. Hence, the multiple webhooks that used to process subscription-related actions will now utilize only one blocking handler, ensuring it cannot run in parallel for several requests for one user.
This is the simplicied version of the code we used to fix the bug:
def sync_app_subscription
PlanChangeSchedule.transaction do
# Prevent concurrent plan updates; if another job attempts to acquire the lock simultaneously, it will wait until this one is completed
PlanChangeSchedule.where(user: user).lock
if actual_subscription && stripe_plan != user.plan
synchronize!
elsif !actual_subscription
cancel_account
end
end
ensure
PlanChangeSchedule.where(user: user).delete_all
end
PlanChangeSchedule is a special table that stores the user’s plan change requests. It’s used to prevent concurrent plan updates. The lock method is used to prevent concurrent plan updates. If another job attempts to acquire the lock simultaneously, it will wait until this one is completed. The synchronize! method is used to synchronize the user’s plan with the actual Stripe subscription. The cancel_account method is used to cancel the user’s account if there is no actual subscription.
After fixing the bug, we transferred all users who had not used the app in the last 90 days to the free plan. There were 391 such accounts. The remaining users got moved to the paid subscription. In the end, the result looked like that:
- 30 users got moved to the free plan;
- For the rest 48, we tried to reactivate the subscription. 19 of which got successfully reactivated. 5 of them, could not have created the subscription due to a missing payment method. 24 of them created subscriptions but with the payment failing, they will be moved to the free plan after 3 failed attempts, or remain active if paid.
That resulted in roughly a $525 immediate increase in Monthly Recurring Revenue (MRR) and 600$ in potential MRR increase if all the users with failed payments will be reactivated.
Preventing future discrepancies
To prevent future discrepancies, we set up a monitoring system that checks for new discrepancies every week. We use Metabase for this purpose. We set up a dashboard that shows the number of discrepancies. We also set up alerts that notify us when the number of discrepancies exceeds a certain threshold. All of that was done using Metabase and SQL.
Conclusion
Asynchronous communication between services is a painful point. It can lead to customer dissatisfaction, losses to the business, and increased workload for the customer support team. This post shows how we deal with these kinds of issues. Efficiently solving them requires deep expertise in SQL, the business, the tech stack, data analysis, and programming.
Happy coding and bug-free apps to you, our reader!